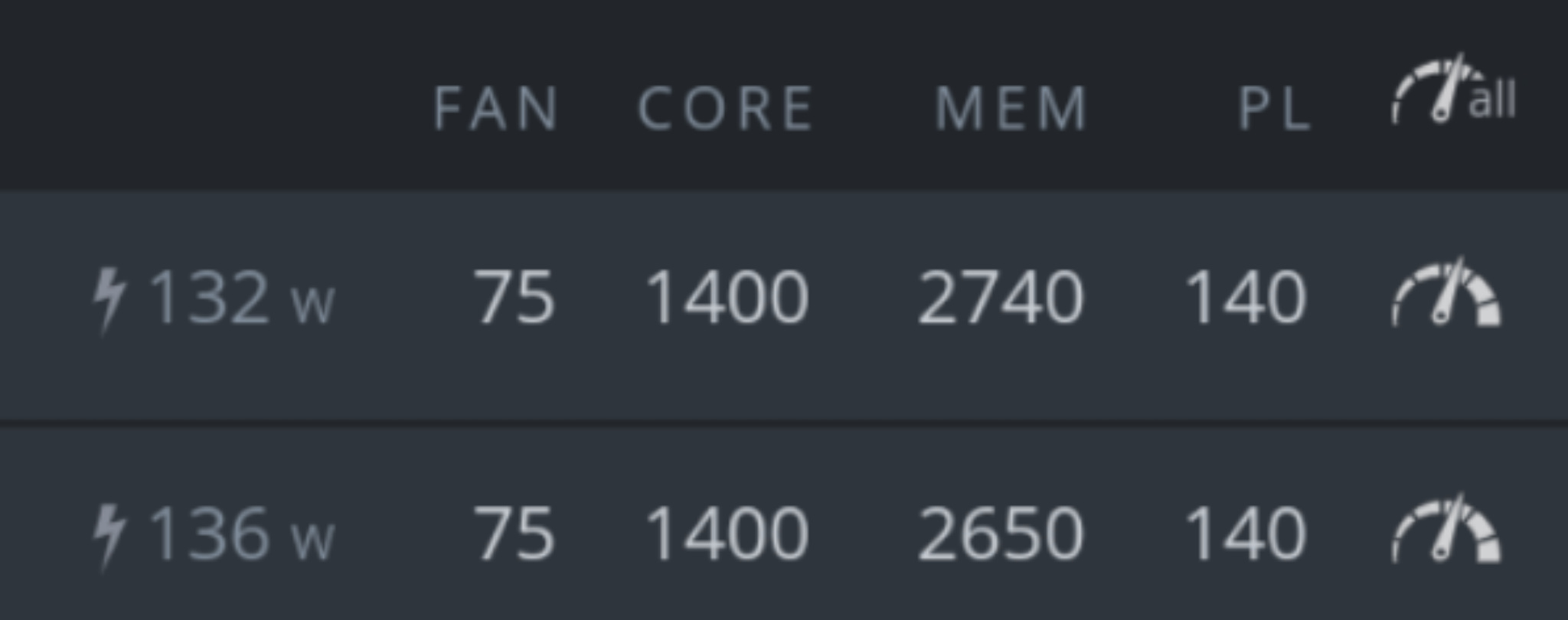
don’t throw away your GPU’s once Ethereum goes v2.0
We will support GPU’s < end Q2 2022 in dedicated nodes.
GPU’s are amazing for lots of workloads like
- deep learning
- artificial intelligence
- compression/encryption
At start GPU’s will only be supported in dedicated nodes.
We expect this to drive a lot of compute traffic to TFGrid.
Stay tuned.
Kristof