
Hi,
First let me say thanks to all of you who are creating deployments and testing the ThreeFold Grid as users. Your experiences are valuable contributions to our ecosystem, as we learn and build new cloud technology together.
We also want to remind everyone that TFGrid 3 is a decentralized cloud carried by thousands of farmers. There are no service level agreements or contracts in place, beyond the requirements that nodes achieve certain uptime targets in order to mint TFT. This means that nodes can come and go from the network at any time, and this can have an impact on your workloads.
The truth is that even in a major cloud environment, backups are still an essential aspect of any deployment. In this post we’ll cover some ideas for backing up your workloads and also some ideas for how to make deployments more reliable.
Backups
Any data that’s not backed up is subject to loss—simple as that. There are a variety of backup tools you can use in a Linux environment. A good and popular option is Restic, which can backup to any S3 service.
You can host an S3 server on the TFGrid, using free and open source software like Garage or Minio. There are also plenty of other options including both decentralized and centralized services such as Storj, Sia, and Backblaze, which you can use as a backend to do your backup too.
Improving reliability
Various methods are available to improve the reliability of deployments. The nature of the workload is an important factor in deciding which methods are appropriate.
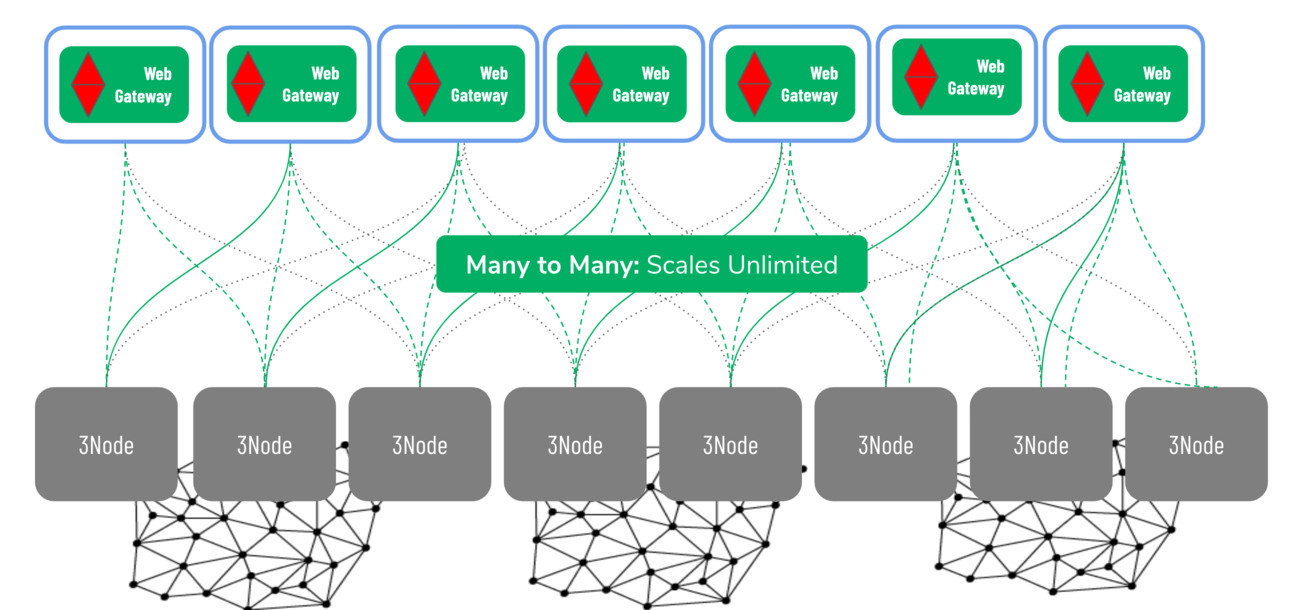
In general, ThreeFold’s web gateways provide a low cost way to create multiple points of entry toward your deployment. When combined with redundant backends, failure of both individual nodes and entire farms can be tolerated.
Web Gateway - Example with Static Site
Static sites are a simple case that can illustrate how to use gateways to create additional reliability. In this case we don’t need to worry about replicating any new data aside from the site content itself.
Here are the components of this deployment:
- Two backend web servers hosting the site content (these servers don’t need any public IP addresses)
- Two gateways, both pointing to each backend server and configured to use a custom domain
- DNS name for the site is configured to use both gateways. This results in round robin load balancing over the two backends, and automatic failover if either backend or gateway goes down (this is done well by modern web browsers)
Assuming the backends and gateways are both spread across different farms, this setup can tolerate the failure of an entire farm.
Here is a visual example of how gateways can be used:
Kubernetes
Kubernetes is a tool for creating computing clusters that manage containerized deployments. A Kubernetes cluster with a high availability control plane and multiple worker nodes can tolerate the failure of any node in the system.
Using Kubernetes is generally only a way to protect against the failure of individual nodes. Operating Kubernetes clusters with control plane nodes spread over wide geographical areas is generally not recommended. It may be possible, however, to run Kubernetes with nodes spread over multiple farms, assuming the latency between farms is low enough.
Operating Kubernetes, especially handling all considerations related to replicating data and handling networking, takes considerable skill. If you have experience running Kubernetes on the ThreeFold Grid, we’d love to hear your story.
Clustering
Databases, along with file assets, are a primary site of application state. Simply backing up a database periodically might create too large of a window where data can be lost, and restoring a database from a backup might create too much of a service interruption.
Many databases support replication, and some even support high availability configurations with automatic failover, either out of the box or using addons. Operating a database replica and having a failover strategy can improve overall deployment reliability, especially if replicas span two or more farms.
Clustered filesystems can also be a way to provide automatic replication and high availability for files. GlusterFS is one example of a clustered filesystem that can run in ThreeFold VMs. We have a basic example of this in the Terraform section of the manual.
Do note that clustered filesystems also typically require low latency network links for reliable performance and therefore aren’t a general solution to creating reliability across multiple sites. Backup and file syncing solutions may be a better fit for replicating across any significant geographical distance.
Conclusion
With a bit of careful planning and implementation of the strategies mentioned in this post, workloads on the ThreeFold Grid can be made reliable and able to recover in the case of node and farm outages. If you have any questions about the ideas mentioned here or how to implement them, please feel free to write a reply below, or ask in our testers chat on Telegram.