
Imagine a server with a HDD of 16TB in the QSFS goes offline, how long doest it take to rebuild this 16TB on another or multiple other servers? How is it done?
Offline HDD QSFS [Closed]
Good question @animalfarm !
To understand QSFS, you could read this documentation: https://threefoldfoundation.github.io/books/technology/technology/qsss/qss_algorithm.html
An important part:
"This system can be used as backend for content delivery networks.
Imagine a movie being stored on 60 locations from which we can loose 50 at the same time.
If someone now wants to download the data the first 10 locations who answer fastest will provide enough of the data parts to allow the data to be rebuild.
The overhead here is much more compared to previous example but stil order of magnitude lower compared to other cdn systems."
Thus, the data rebuild is done automatically with QSFS. The rebuild time should depend on the bandwidth available in the overall system.
I’ll be curious to read what others have to say.
Hope it helps!
And how does ThreeFold use ReedSolom ECC differently from systems like Google’s Colossus?
(apart from the fact that it is made accessible for everybody as implemented in QSFS, everyone can choose hardware, number of shards,… are there other crucial differences on a technical level?)
Add to that, what is meant by 20x less overhead compared to classic systems? Which classic systems exactly?
Maybe these are also relevant question to include in the upcoming community call.
Thanks for the provided link, did not find this resource before!
1 Like
Good questions.
About the overhead, here’s the place where it explains the 20% vs 400%:
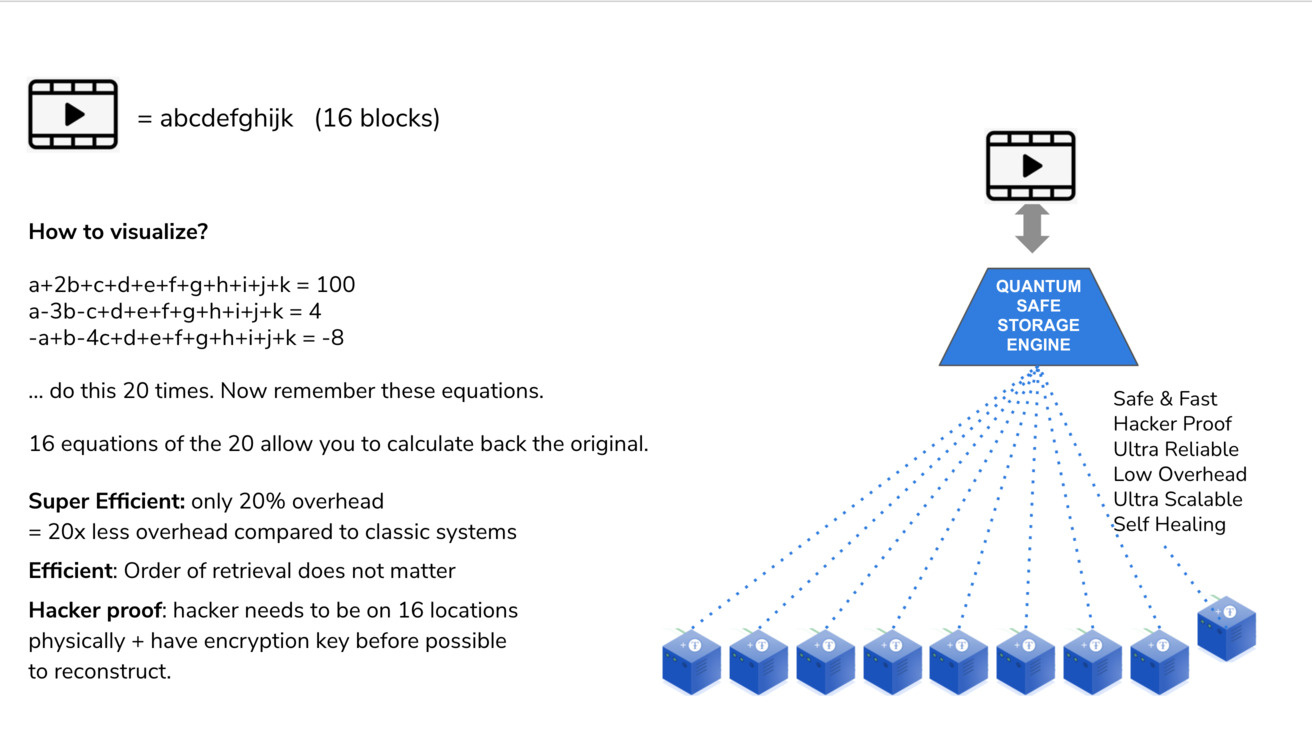
“Each object is fragmented into 16 parts. So we have 16 original fragments for which we need 16 equations to mathematically describe them. Now let’s make 20 equations and store them dispersedly on 20 devices. To recreate the original object we only need 16 equations, the first 16 that we find and collect which allows us to recover the fragment and in the end the original object. We could lose any 4 of those original 20 equations.”
" The likelihood of losing 4 independent, dispersed storage devices at the same time is very low. Since we have continuous monitoring of all of the stored equations, we could create additional equations immediately when one of them is missing, making it an auto-regeneration of lost data and a self-repairing storage system. The overhead in this example is 4 out of 20 which is a mere 20% instead of (up to) 400%."
That is indeed clear but do other cloud providers actually still use systems with 400% overhead? As far as I understand Google has been using Reed Solomon encoding for over a decade.

Same thing here, how is QSFS 10x more efficient than classic cloud storage systems? Which systems are being referred to? Are there any benchmarks or backing for these claims? Using Reed Solomon is not a new thing in cloud storage systems, so I’m really wondering where this extra magnitude of efficiency is coming from  .
.